

还记得你第一次打开 WebUI,用上第一个 SD 模型的那天吗?
你对着英文教程添加CheckPoint和LoRA,调参数、试提示词,盯着那根进度条缓缓滑动——屏幕闪烁、风扇呼呼转,噪点一点点汇聚成光影与形状,第一张AI生的图,出来了!
(上图为2023年初版LibLibAI首页)
那是2023 年,那是开源绘画真正点燃的第一年。无数图像创作者在开源生态里汇聚、分享、碰撞、彼此启发,一些自称为“炼丹师”的人们开始出现。
LiblibAI 就是在那时起步,慢慢成长为中国最大的多模态模型社区。2000 万创作者在这里训练 LoRA、搭建工作流,很多人为了热爱自发宣传这座“小破站”。在中国,每三个设计师,就有一位用过 LiblibAI。
在公司资金最紧张的时候,我们依然选择补贴创作者,两年多来累计发放了超千万创作者激励,只为了让AI创作这件事变得更自由、更容易。
过去两年多,多模态的开源与闭源犹如两条洋流,彼此交汇、激荡。而在随后近一段时间里,开源生态有些遇冷,我们也似乎变得有些沉默。沉默于喧嚣之后,也沉淀于变化之中。与此同时,AI 视觉创作的世界变得更加热闹:图像、视频、声音、三维空间——新的模型、新的玩家不断涌现。两千万创作者依然在这里,他们创作、分享、交流,也在提出新的困惑和问题,越来越多的新用户不会用了、也找不到方向。
我们看在眼里,更加坚定:
不能只做工具,要把零散的能力真正整合起来,变成一站式的创作体验。
让AI创作更简单、更专业?
让创作者的灵感,不止开始于此,更能在这里持续繁荣生长?
我们始终相信,真正的创新,诞生于无数创作者的共同进化,根植于社区的力量。
LiblibAI 2.0是什么
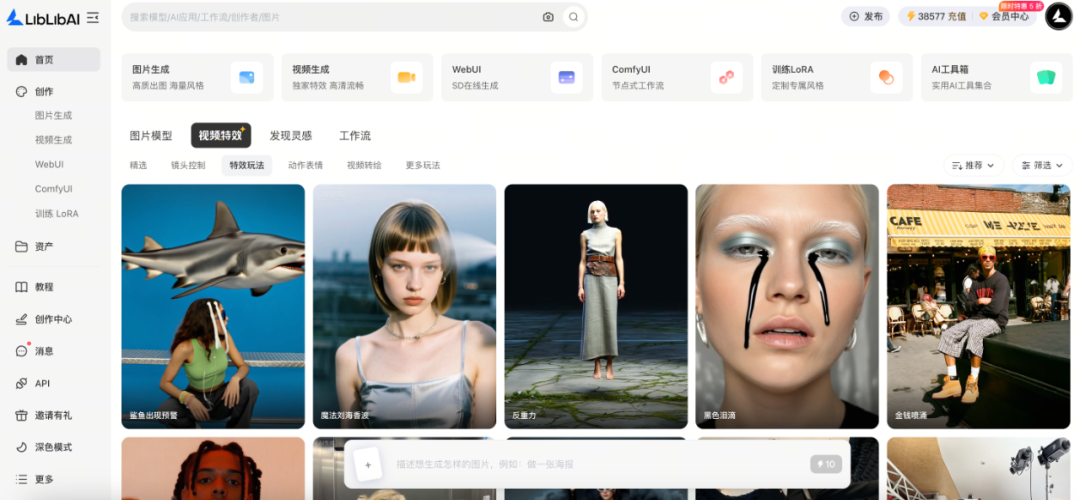
于是,有了 LiblibAI 2.0。
它不只是模型的聚合地,也不仅仅是工具的合集,而是一间真正属于创作者的 AI 专业创作工作室。
在这里,你不必再为工具分散而焦虑,不再花时间在十几个会员与素材平台之间切换。只需打开 LiblibAI,就能像在自己的工作室里一样——从灵感到成品,一气呵成。
还能与成千上万的创作者一起试验、突破、分享灵感,找到素材和伙伴。
全新的 LiblibAI 2.0 汇集了我们对此刻AI创作的理解:
- 它拥有 极简生成器,让视频与图像生成在同一界面完成,零学习成本、即点即用;
- 它兼容 开源与闭源模型,图像方面一次集齐 Qwen Image、F.1、Kontext、Seedream4、MidjourneyV7等最强阵容;它内置 Kling、Hailuo、Vidu、WAN 等顶级视频模型,搭载 500+ 独家专业视觉特效,让每一帧都能达到影视级品质;
- 它整合了 全球最大图片风格开源模型库,覆盖插画、摄影、电商、海报、IP 等各类视觉风格,让最专业的视觉创作者能够快速找到灵感所需的风格与质感,也让初学者在一次次尝试中,逐渐找到属于自己的创作语言。
- 它支持 AI 工作流批量化处理——扩图、高清、换脸、产品精修等高频流程,一键批量完成,效率提升数倍。
除了全新的界面与体验,我们也保留了熟悉的 WebUI 和 ComfyUI。你可以在新的平台上继续原有的工作流,也可以自由组合新的方式,拼一张属于自己的创作桌。

© 版权声明
文章版权归作者所有,未经允许请勿转载。


